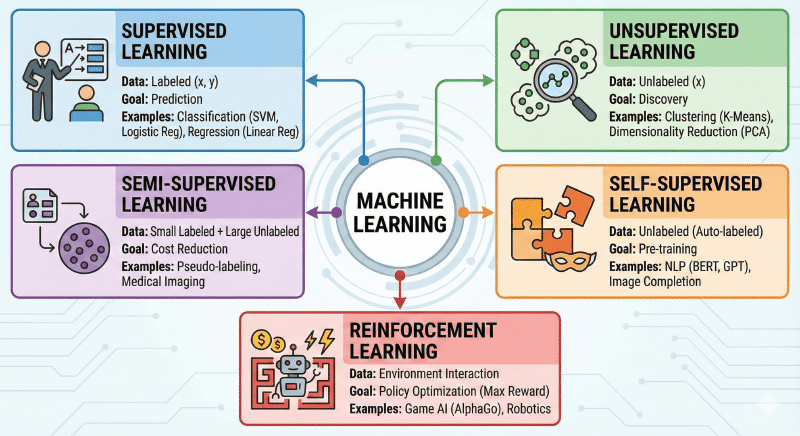
机器学习五大分类
前言:机器学习的本质
机器学习(Machine Learning)的核心任务是:通过算法让计算机从数据中学习规律,而不是通过人类手写代码规则。
根据 “数据里有没有标准答案(标签)”以及“学习的目标是什么”,我们将其分为以下五大类。
第一类:监督学习 (Supervised Learning)
这是目前工业界应用最广泛、最成熟的类型。你生活中见到的绝大多数 AI(如人脸识别、房价预测、垃圾邮件拦截)都属于这一类。
核心定义
-
数据形态:训练数据既包含输入特征 ( x ),也包含对应的正确答案/标签 ( y )。
- 例子:一张猫的照片 ( x ) + 标签“猫” ( y )。
-
学习目标:寻找一个映射函数 f ,使得 y = f(x) 。当有新的未知数据 x’ 输入时,模型能预测出准确的 y’ 。
-
直观比喻:有老师指导的学生。老师给你发了习题册(输入)和标准答案(标签)。你做题,对答案,发现错了就修改自己的解题思路(更新模型参数),直到能在考试中拿高分。
两大核心任务
根据标签 y 的数据类型,监督学习严格分为两类:
A. 回归 (Regression) —— 预测“多少”
-
标签类型:连续的数值。
-
数学直觉:试图在数据空间中画一条线(或一个面),让所有数据点离这条线的距离之和最小(拟合)。
-
典型场景:
-
房价预测:输入地段、面积,输出价格(300万, 305.5万…)。
-
股票预测:输入历史走势,输出明日股价。
-
气温预测:输出具体的摄氏度。
-
-
常用算法:线性回归 (Linear Regression)、SVR (支持向量回归)、XGBoost (回归模式)。
B. 分类 (Classification) —— 预测“哪个”
-
标签类型:离散的类别。
-
数学直觉:试图在数据空间中画一条“分界线”(决策边界),把不同类别的点分开。
-
典型场景:
-
二分类:是否垃圾邮件(是/否)、是否患病(阳性/阴性)。
-
多分类:手写数字识别(0-9)、图像分类(猫/狗/鸟/车)。
-
-
常用算法:SVM (支持向量机)、逻辑回归 (Logistic Regression)、决策树、随机森林、KNN。
优缺点分析
-
优点:目标非常明确,准确率通常很高,模型好坏很容易评估(看准确率是多少)。
-
缺点:数据标注成本极高。需要大量人力去给数据打标签(比如请医生看几万张片子),被称为“有多少人工就有多少智能”。
第二类:无监督学习 (Unsupervised Learning)
核心定义
-
数据形态:只有输入特征 ( x ),没有标签 ( y )。只有题目,没有答案。
-
学习目标:模型必须依靠自己去挖掘数据内部隐藏的结构、模式或分布规律。
-
直观比喻:牙牙学语的婴儿。没人教婴儿“主谓宾”的语法规则,但婴儿听得多了,自然能总结出语言的规律,或者分辨出爸爸和妈妈的声音是不同的类别。
三大核心任务
A. 聚类 (Clustering) —— “物以类聚”
-
目标:计算样本之间的相似度(通常用距离表示),将相似的样本自动归为一组(簇)。
-
应用:
-
用户分群:电商平台根据购买记录,自动把用户分成“高消费群”、“羊毛党”、“母婴群”。
-
异常检测:大多数数据聚在一起,那些离得很远的数据点可能就是“异常”(如信用卡欺诈)。
-
-
算法:K-Means (K均值)、DBSCAN (基于密度的聚类)。
B. 降维 (Dimensionality Reduction) —— “去伪存真”
-
目标:在保留主要信息的前提下,把高维数据(几千个特征)压缩成低维数据(几十个特征)。
-
原因:高维数据计算太慢,且包含很多噪音(无用信息)。
-
应用:
-
可视化:把 100 维的数据压到 2 维,画在纸上给人看。
-
存储压缩:减少硬盘占用。
-
-
算法:PCA (主成分分析)、t-SNE。
C. 关联规则 (Association) —— “发现共现”
-
目标:发现数据项之间同时出现的概率。
-
应用:购物篮分析。经典的“啤酒与尿布”案例:数据发现买尿布的人通常也会买啤酒。
优缺点分析
-
优点:不需要人工标注,数据获取成本极低(互联网上全是无标签数据)。能发现人类未知的规律。
-
缺点:结果具有不可控性(你不知道它分出来的类到底代表什么),模型很难量化评估。
第三类:半监督学习 (Semi-Supervised Learning)
这是解决现实世界“数据多但标签少”问题的折中方案。
核心定义
-
数据形态:少量的有标签数据 + 大量的无标签数据。
-
背景:在医学、工业等领域,收集数据很容易(拍照就行),但请专家打标签非常贵。
-
学习机制:“以点带面”。
-
老师带入门:先用那一点点“有标签数据”训练一个初始模型(老师)。
-
自己刷题:用这个模型去预测那些“无标签数据”。
-
伪标签 (Pseudo-Labeling):挑选出模型最有把握(置信度高)的那些预测结果,给它们贴上标签(虽然是机器猜的,但我们暂时当它是真的)。
-
再训练:把这些新贴标签的数据加入训练集,扩大规模再次训练。
-
关键假设
-
聚类假设:如果两个点在空间里靠得很近(属于同一个簇),它们很可能拥有相同的标签。
-
流形假设:数据分布在一个低维的流形上,标签会沿着流形平滑传播。
应用场景
-
医学影像分析:只有少数片子有医生确诊,但有海量未看过的片子。
-
网页/文本分类:互联网网页无穷无尽,人工无法全标。
第四类:自监督学习 (Self-Supervised Learning)
注意:这是目前 AI 领域(特别是大模型 ChatGPT, BERT)最前沿、最重要的基石。它形式上属于无监督(没人工标签),但本质上是监督(自己造标签)。
核心定义
-
数据形态:无标签 ( x )。
-
学习机制:“前置任务” (Pretext Task)。
-
模型不依赖人工标签,而是通过巧妙地修改数据本身,构造出“输入”和“标签”。
-
即:从数据的一部分预测另一部分。
-
-
直观比喻:做完形填空。
-
把文章中的几个字遮住(Mask),让 AI 去猜被遮住的字是什么。
-
虽然没有标准答案,但“原文”就是答案。猜对了,说明 AI 读懂了上下文和语法。
-
典型任务与原理
-
NLP (自然语言处理):
-
BERT 模式:句子中间挖空,让 AI 填空。学到的是双向理解能力。
-
GPT 模式:给前半句,让 AI 预测下一个字。学到的是生成能力。
-
-
CV (计算机视觉):
-
图像补全:把图片挖掉一块,让 AI 脑补。
-
拼图预测:把图片切成九宫格打乱,让 AI 拼回原样。
-
对比学习 (Contrastive Learning):让 AI 识别同一张图的两个不同裁剪版本是“一对”,而和其他图不是“一对”。
-
核心意义 (Pre-training)
- 预训练大模型:通过自监督学习,AI 可以在几十TB的互联网文本上“海量阅读”,学到通用的语言知识。然后只需要一点点人工数据微调 (Fine-tuning),就能变成专家。
第五类:强化学习 (Reinforcement Learning, RL)
这一类完全不同于以上四种“静态数据学习”,它是“动态交互学习”,是通向通用人工智能(AGI)的关键。
核心定义
-
数据形态:没有现成的静态数据集。数据是在智能体 (Agent) 与 环境 (Environment) 的交互过程中实时产生的。
-
学习机制:“试错” (Trial-and-Error)。
- 智能体观察环境 -> 做出动作 -> 环境反馈奖励或惩罚 -> 智能体更新策略。
-
目标:最大化长期累积奖励(Long-term Reward)。它不看这一步赢没赢,看的是最后能不能通关。
-
直观比喻:驯兽 / 玩闯关游戏。
-
小狗坐下了 -> 给骨头吃(奖励 +1) -> 小狗学会坐下。
-
小狗乱拉尿 -> 训斥(惩罚 -10) -> 小狗不再乱拉。
-
核心三要素 (MDP 过程)
-
状态 (State):现在的情况(如:围棋的盘面,王者荣耀的屏幕画面)。
-
动作 (Action):我能做什么(如:落子在何处,按哪个技能键)。
-
奖励 (Reward):环境给的反馈(如:赢了+100分,输了-100分,吃金币+1分)。
核心难点:探索与利用
-
利用 (Exploitation):根据现在的经验,选那个奖励最高的动作(贪婪)。
-
探索 (Exploration):尝试一下没做过的动作,虽然可能输,但也可能发现新大陆(获得更高分)。
-
强化学习就是在“稳扎稳打”和“冒险尝试”之间找平衡。
应用场景
-
游戏 AI:AlphaGo(围棋)、OpenAI Five(Dota2)。
-
机器人控制:波士顿动力机器狗(学习怎么走不摔倒)。
-
自动驾驶:学习在复杂路况下如何变道、超车。
总结:如何记忆?
-
监督学习:照着答案学。有题有答案,做预测。
-
无监督学习:自己找规律。有题没答案,做分类/降维。
-
半监督学习:举一反三。少量答案+大量题目,省钱。
-
自监督学习:自己出题自己做。自动造标签,预训练大模型。
-
强化学习:在试错中成长。环境交互,求最后赢。